1. 引言(Introduction)
我们意识到,我们的大部分计算都涉及对输入中的每个逻辑 “记录” 应用 map 操作,以便计算一组中间键 / 值对,然后将 reduce 操作应用于共享同一键的所有值,以便适当地组合派生数据。我们使用具有用户指定 map 和 reduce 操作的函数模型,使我们能够轻松地并行化大型计算,并使用重新执行作为容错的主要机制。
这项工作的主要贡献是一个简单的和强大的接口,可实现自动并行化和大规模计算的分布,结合起来使用此接口的实现大型商用PC集群上的高性能。
2. 编程模型(Programming Model)
Map 和 Reduce 的定义与功能
Map(映射):是由用户编写的函数,它接受一个输入键值对,然后对输入数据进行处理,产生一组中间键值对。例如在单词计数的例子中,Map 函数会读取文档内容(值),将文档中的每个单词作为键,“1” 作为值,输出一系列 < 单词,“1”> 这样的中间键值对,表示每个单词出现了一次。其作用是将大规模数据的处理分解为对每个独立数据块(逻辑 “记录”)的操作,为后续的合并处理提供基础数据。
Reduce(归约):同样由用户编写,它接受一个中间键以及与该键相关联的一组值。Reduce 函数的主要任务是将具有相同键的值进行合并处理,通常是将这些值进行某种计算(如求和、连接等),最终生成可能更小的一组值,一般每个 Reduce 调用产生零个或一个输出值。以单词计数为例,Reduce 函数会接收一个单词(键)和该单词对应的所有计数(值的列表),然后将这些计数相加,得到该单词的总出现次数,输出 <单词,总次数> 这样的键值对。Reduce 操作实现了对中间数据的合并和聚合,从而得到最终想要的结果形式。
Map 和 Reduce 函数共同构成了 MapReduce 编程模型的核心,通过这种分而治之的方式,能够在大规模集群上高效地处理海量数据。
典型使用案例(如单词计数)
大型文档集合中每个单词的出现次数的问题
| |
map: 遍历文档内容中的每个单词w。对于每个单词,使用EmitIntermediate(w, "1")发出一个中间键值对,其中键是单词w,值是字符串"1"。这表示该单词在当前文档中出现了一次(以简单的计数为 1 来表示每次出现)。
reduce: 遍历迭代器values中的每个值v。对于每个值,将v从字符串转换为整数并累加到result中。最终result将是该单词在所有文档中的总出现次数。
类型(Types)
| |
键值对的域是指键和值所属的数据类型范围或集合。
- 输入键值对的域(input keys and values domain): 文档名和文档内容组成的键值对集合
- 中间键值对与输出键值对的域:相同,由键:单词(字符串),值:单词个数(整数)来组成
ps: 至于为什么 list(k2,v2) 与 list(v2) 不相同是因为在 reduce 函数里默认是 k2 这个键下的内容
域的作用和意义(Domain)
不同的域有助于清晰地区分 MapReduce 处理过程中不同阶段的数据类型和结构,使得程序能够正确地处理数据在各个阶段的转换和操作。
用户在编写 Map 和 Reduce 函数时,需要根据这些域的定义来正确处理数据类型的转换(因为 C++ 实现传递的是字符串,用户代码要负责在字符串和实际合适的数据类型之间转换),以确保整个 MapReduce 作业能够准确地计算和生成期望的结果。
例如,在 Map 函数中,要将输入的字符串类型的文档内容正确解析为单词等合适的数据类型,然后以符合中间键值对域要求的格式输出中间结果;在 Reduce 函数中,要正确处理来自相同域的中间键值对数据,最终生成符合输出键值对域要求的结果。
3. 实现细节(Implementation)
系统架构与流程概览
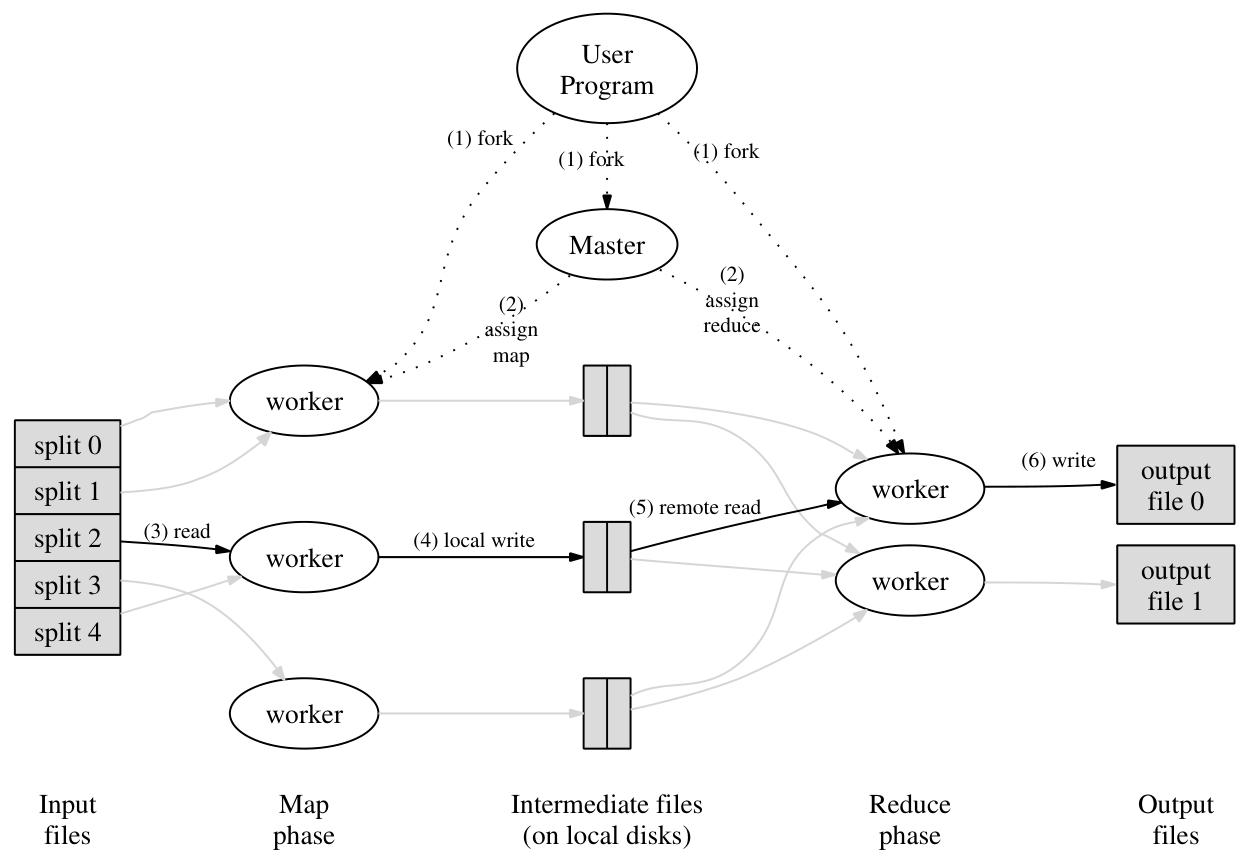 Figure 1: Execution overview
Figure 1: Execution overview
这张图展示了一个 MapReduce 计算模型的工作流程。MapReduce 是一种用于处理大规模数据集的编程模型,它通过将任务分解成多个子任务,并在集群中的多个节点上并行执行,最后将结果合并起来。以下是对图中各个部分的详细解释:
User Program(用户程序):
- 位于图的顶部,是整个流程的起点。用户程序启动并控制整个 MapReduce 作业。
- 用户程序通过
fork操作创建一个Master进程和多个worker进程。
Master(主进程):
- Master 负责将输入数据分成多个
split,并将map和reduce任务分配给各个worker。
主节点的信息传递角色:
- 在
MapReduce计算中,存在大量的中间数据。当Map任务处理完输入数据的一个分片后,会产生中间结果并存储为中间文件。这些中间文件可能分布在不同的节点上,而主节点就像是一个信息枢纽(conduit)。 - 它负责将这些中间文件的位置信息(例如在哪个节点的哪个磁盘路径下)从完成
Map任务的节点传递到需要这些数据的Reduce任务所在的节点。这是因为Reduce任务需要知道从哪里获取与自己相关的中间数据来进行进一步处理。
主节点对Map任务信息的存储:
- 对于每个完成的
Map任务,主节点会记录该任务产生的中间文件区域的相关信息。这里的“R个中间文件区域”表示根据用户指定的Reduce任务数量(R),Map任务会将中间数据分成R个部分(分区)存储。例如,如果R = 5,那么Map任务可能会将中间数据分成5个区域存储,每个区域对应一个Reduce任务可能需要处理的数据。 - 主节点存储这些区域的位置(如节点IP、磁盘路径等)和大小信息。这有助于主节点有效地管理和协调数据的传输,以及在
Reduce任务需要数据时能够准确地提供信息。
信息更新与推送机制:
- 随着
Map任务的逐步完成,主节点会不断收到关于新完成的Map任务的中间文件位置和大小的更新信息。这些更新是实时的,以便主节点能够及时掌握数据的分布情况。 - 一旦主节点获取到这些更新信息,它会将相关的中间文件位置信息推送给正在进行
Reduce任务的工作节点。这种推送是增量式的(incrementally),即只推送与当前正在进行的Reduce任务相关的新完成的Map任务的信息,避免不必要的数据传输和节点资源浪费。这样,Reduce任务所在的工作节点就能够准确地知道从哪里获取所需的中间数据,从而顺利进行后续的处理操作,最终实现整个MapReduce计算的高效执行。
- Master 负责将输入数据分成多个
Worker(工作进程):
- 图中有多个
worker进程,分布在图的中间和底部。 worker进程负责执行map和reduce任务。
- 图中有多个
Input Files(输入文件):
- 位于图的左下角,代表原始输入数据。
- 输入数据被分成多个
split(数据分片),如split 0、split 1等。
Map Phase(映射阶段):
- 每个
worker读取一个split(通过read操作),然后执行map任务。 map任务的结果以中间文件(Intermediate files)的形式存储在本地磁盘上。
- 每个
Intermediate Files(中间文件):
- 位于图的中间偏右位置,代表
map阶段的输出。 - 这些中间文件存储在本地磁盘上,供
reduce阶段使用。
- 位于图的中间偏右位置,代表
Reduce Phase(归约阶段):
worker进程从本地磁盘上读取中间文件(通过remote read操作),然后执行reduce任务。reduce任务的结果被写入Output files。
Output Files(输出文件):
- 位于图的右下角,代表最终的输出结果。
- 这些文件是
reduce阶段的输出,包含了最终的计算结果。
成功完成后,MapReduce 执行的输出可在 R 输出文件中获取(每个归约任务一个文件,文件名由用户指定)。通常,用户不需要将这些 R 输出文件合并为一个文件——他们经常将这些文件作为另一个 MapReduce 调用的输入,或者在另一个能够处理被划分到多个文件中的输入的分布式应用程序中使用它们。
整个流程通过worker进程之间的协作和数据交换,实现了大规模数据的并行处理和计算。Master进程负责协调和分配任务,确保整个作业的顺利进行。
Master 和 Worker 的角色与任务分配
Master:
There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task. 有 M map 任务和 R reduce 任务要分配。master 选择空闲的 worker 并为每个 worker 分配一个 map 任务或一个 reduce 任务。
Worker:
A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined $Map$ function. The intermediate key/value pairs produced by the Map function are buffered in memory. 被分配了映射(map)任务的工作进程(worker)读取相应输入分片(input split)的内容。它从输入数据中解析出键/值对,并将每一对传递给用户定义的映射函数($Map$ function)。由映射函数生成的中间键/值对被缓存在内存中。
The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition. 执行归约(reduce)任务的工作进程(worker)会遍历已排序的中间数据,对于遇到的每个唯一的中间键(intermediate key),它会将该键以及相应的一组中间值传递给用户的归约函数(Reduce function)。归约函数的输出会被追加到这个归约分区的最终输出文件中。
容错机制(Fault Tolerance)
Since the MapReduce library is designed to help process very large amounts of data using hundreds or thousands of machines, the library must tolerate machine failures gracefully.
工作线程故障(Worker Failure)
Master 会定期 ping 每个 worker。如果在一段时间内未收到 worker 的响应,则 master 会将该 worker 标记为失败。worker 完成的任何 map 任务都将重置回其初始空闲状态,因此有资格在其他 worker 上进行调度。同样,失败的工作程序上正在进行的任何 map 任务或 reduce 任务也会重置为 idle (空闲),并有资格重新安排。
已完成 reduce 任务
已完成的映射任务在失败时重新执行,因为其输出存储在失败计算机的本地磁盘上,因此无法访问。已完成的 reduce 任务不需要重新执行,因为它们的输出存储在全局文件系统中。
未完成 reduce 任务
当执行 map 任务的 Worker A 失败时,该任务由 Worker B 执行。正在执行的包含 map 的 reduce 程序会收到 map 任务重新执行的通知(强调的是 Reduce 任务获取数据来源的调整,即map 任务输出的中间数据的存储位置的改变)。
主站故障(Master Failure)
很容易让主节点定期写入上述主数据结构的检查点。如果主节点任务失败,可以从最后一个检查点状态启动一个新副本。然而,鉴于只有一个主节点,其出现故障的可能性不大;因此,我们当前的实现是,如果主节点出现故障,则中止 MapReduce 计算。客户端可以检查这种情况,如果需要,可以重试 MapReduce 操作。
故障存在时的语义(Semantics in the Presence of Failures)
原子提交机制概述
为了确保在分布式环境下 MapReduce 计算结果的正确性和一致性,即使存在故障也能得到与无故障顺序执行相同的输出,系统依赖于对 Map 和 Reduce 任务输出的原子提交(atomic commits)机制。
任务输出写入临时文件
Map 任务:在执行过程中,每个正在进行的 Map 任务会将其产生的中间结果输出写入 R 个私人临时文件(private temporary files)。这里的 R 是由用户指定的 Reduce 任务数量。这意味着 Map 任务会根据后续 Reduce 任务的数量对其输出进行分区,每个分区对应一个 Reduce 任务。例如,如果有 5 个 Reduce 任务(R = 5),那么一个 Map 任务会产生 5 个临时文件,分别用于存储与这 5 个 Reduce 任务相关的中间数据。这样做的目的是为了在后续的 Reduce 阶段,能够方便地将相同键的数据发送到对应的 Reduce 任务进行处理。
Reduce 任务:Reduce 任务则产生一个临时文件来存储其计算结果。这个临时文件在 Reduce 任务执行过程中用于暂存中间或最终的计算结果,等待合适的时候转换为最终输出文件。
Map 任务完成后的通信与记录
消息发送:当一个 Map 任务完成时,执行该任务的工作节点(worker)会向主节点(master)发送一个消息。这个消息中包含了该 Map 任务所产生的 R 个临时文件的名称。这使得主节点能够知道这些临时文件的位置信息,以便在后续的 Reduce 任务执行过程中,将正确的中间数据提供给相应的 Reduce 任务。
主节点处理:主节点收到消息后,会检查该 Map 任务是否已经完成过(可能由于网络延迟等原因收到重复消息)。如果是已经完成的 Map 任务,主节点会忽略该消息;否则,主节点会将这 R 个文件的名称记录在其内部的数据结构中。这个数据结构用于跟踪和管理 Map 任务的输出位置信息,以便在 Reduce 任务需要时能够准确地获取数据。
归约任务完成时的操作
当一个归约(reduce)任务完成时,执行归约任务的工作节点(reduce worker)会以原子操作的方式将其临时输出文件重命名为最终输出文件。如果同一个归约任务在多台机器上执行(例如,由于节点故障等原因,导致该任务在不同机器上重试),那么对于同一个最终输出文件会执行多次重命名操作。我们依赖底层文件系统提供的原子重命名操作来确保最终的文件系统状态中只包含由一次归约任务执行所产生的数据。
较弱语意?
并不是很清楚,下次再来看看
本地性优化(Data Locality)
在计算环境中网络带宽稀缺,为节省带宽,利用由 GFS 管理、存储于集群机器本地磁盘的输入数据这一特性。 GFS 将文件分成64MB块,每块通常存3个副本于不同机器。 MapReduce 主节点考虑输入文件位置,优先将映射任务调度到含对应数据副本的机器,不行则调度到数据副本附近机器。在集群大量工作节点运行大型 MapReduce 操作时,多数输入数据可本地读取,不消耗网络带宽 。
任务粒度与动态负载平衡
任务粒度: 是指任务被划分的精细程度。在 MapReduce 中,通过将整个计算过程划分为映射(Map)和归约(Reduce)两个主要阶段,并进一步将这两个阶段细分,来控制任务粒度。将 Map 阶段细分为 M 个部分,Reduce 阶段细分为 R 个部分。这种细分使得每个部分成为一个相对独立的任务单元,这些任务单元的大小和数量决定了任务粒度。
理想任务粒度的设定: 理想情况下,M 和 R 应该远大于工作节点(worker machines)的数量。这是因为较细的任务粒度可以让每个工作节点有机会执行多个不同的任务。如果任务粒度太粗,即 M 和 R 接近或小于工作节点数量,可能会导致某些工作节点在完成自身分配的少量任务后处于闲置状态,而其他节点可能因任务过重而成为瓶颈,从而无法充分利用集群的计算资源。较细的任务粒度能够实现更好的动态负载均衡,使工作节点的资源得到更充分的利用,提高系统的整体性能。
任务粒度对动态负载均衡的影响:每个工作节点执行多个不同任务有助于动态负载均衡。在实际运行中,不同的任务可能具有不同的执行时间和资源需求。当任务粒度较细时,工作节点可以根据自身的负载情况动态地从任务队列中获取新的任务。如果某个工作节点完成了一个任务并且当前负载较低,它可以立即从众多的剩余任务中选择一个执行,这样可以避免工作节点之间的负载不均衡,使得整个集群的计算资源能够得到更合理的分配和利用,提高系统的运行效率。
任务粒度对故障恢复的作用:较细的任务粒度在工作节点出现故障时能够加速系统的恢复。当一个工作节点失败时,它已经完成的许多 Map 任务可以分散到其他所有工作节点上。由于任务粒度较细,有多个 Map 任务可供重新分配,这些任务可以在其他正常工作的节点上继续进行后续处理,而不需要重新执行整个任务。这大大减少了因节点故障而导致的计算损失,加快了系统从故障中恢复的速度,提高了系统的容错性和可靠性。
4. 优化与扩展(Refinements)
分区函数与排序保证
默认分区函数:系统提供了默认的分区函数,通常采用哈希(hashing)的方式,例如 “hash (key) mod R”。这种方式在大多数情况下能够使数据在各个 Reduce 任务之间得到较为均衡的分配,保证计算负载的平衡。
自定义分区函数:在某些特定场景下,用户可能需要根据自己的需求自定义分区函数。例如,当输出键是 URL 时,如果希望同一个主机的所有条目都能被分到同一个输出文件中,就可以使用 “hash (Hostname (urlkey)) mod R” 这样的分区函数。通过自定义分区函数,用户可以更灵活地控制数据的分区方式,以适应不同的业务逻辑和数据处理要求。这使得 MapReduce 在处理各种类型的数据时更具通用性和适应性,能够满足多样化的实际应用场景。
顺序处理保证:在 MapReduce 计算中,对于给定的分区(partition),中间键值对(intermediate key/value pairs)会按照键(key)的递增顺序进行处理。这意味着在每个分区内,数据在进一步处理时是有序的。
Combiner 的应用场景
使用场景与目的:在某些情况下,每个 Map 任务产生的中间键(intermediate keys)存在大量重复,且用户定义的 Reduce 函数满足交换律和结合律时,为减少网络传输的数据量,可使用合并函数。例如在单词计数中,由于单词频率通常遵循 Zipf 分布,每个 Map 任务会产生许多相同单词的计数记录,如 <the, 1>。
执行位置与方式:合并函数在执行 Map 任务的机器上执行。通常,合并函数和 Reduce 函数可使用相同代码实现,二者的区别在于 MapReduce 库对其输出的处理方式。Reduce 函数的输出会写入最终输出文件,而合并函数的输出则写入中间文件,该中间文件将被发送到 Reduce 任务进行进一步处理。
对性能的提升作用:使用合并函数进行部分合并能显著加快某些类型的 MapReduce 操作。例如在单词计数的场景中,通过在 Map 任务节点先对相同单词的计数进行部分求和,再将结果发送到 Reduce 任务进行最终合并,可有效减少网络传输的数据量,从而提高整体计算效率。附录 A 中提供了使用合并函数的示例程序,展示了其具体的使用方式和效果。
输入输出类型与侧写效果
输入类型支持
多种格式支持:
MapReduce库能够读取多种不同格式的输入数据。例如,在 “text” 模式下,将每行视为一个键值对,其中键是文件中的偏移量,值是该行的内容。此外,还支持存储按键排序的键值对序列等其他格式。用户自定义扩展:用户可以通过实现简单的读取器(reader)接口来添加对新输入类型的支持。不过,大多数用户通常只需使用少量预定义的输入类型。读取器不仅可以从文件读取数据,还能从数据库或内存映射的数据结构中读取记录,这为数据的获取提供了很大的灵活性,使得
MapReduce能够处理各种来源的数据。
输出类型支持:类似地,MapReduce 库也支持以多种不同格式产生输出数据,并且用户代码能够方便地添加对新输出类型的支持。这种多样化的输入输出类型支持使得 MapReduce 可以适应不同的数据处理需求,无论是处理文本数据、结构化数据还是其他特定格式的数据,都能够在该框架下找到合适的处理方式,增强了 MapReduce 的通用性和实用性。
跳过错误记录
问题背景:有时用户代码中的错误会导致 Map 或 Reduce 函数在处理某些记录时确定性崩溃,从而阻止 MapReduce 操作完成。虽然修复错误是常规做法,但有时不可行,如错误在第三方库且无法获取源代码,或者在某些情况下忽略少量错误记录是可接受的,例如对大数据集进行统计分析时。
跳过机制实现方式
- 信号处理安装:每个工作进程安装信号处理程序,用于捕获段错误(segmentation violations)和总线错误(bus errors)。
- 记录序号存储:在调用用户的 Map 或 Reduce 操作之前,MapReduce 库将参数的序号存储在全局变量中。
- 错误报告与记录标记:如果用户代码产生信号,信号处理程序会发送包含序号的 “last gasp” UDP 数据包给主节点。主节点在看到特定记录多次失败后,会在下次重新执行相应的 Map 或 Reduce 任务时跳过该记录。通过这种方式,MapReduce 能够在遇到错误记录时尝试继续计算,而不是完全失败,提高了系统在面对部分错误数据时的容错性和计算的整体成功率,使得计算能够在一定程度上容忍错误并继续推进,对于一些对数据完整性要求不是绝对严格的场景非常有用。
5. 性能评估(Performance Evaluation)
- 测试环境描述
- 性能评估案例(如 grep 和排序)
- 对比与性能瓶颈分析
- 备份任务和故障处理对性能的影响
这部分主要通过在大规模集群上对Grep和Sort两个程序的性能测试,展示了MapReduce的性能表现,具体内容如下:
- 集群配置
- 硬件配置:测试在约1800台机器的集群上进行,每台机器配备双2GHz Intel Xeon处理器(启用超线程)、4GB内存、双160GB IDE磁盘和千兆以太网链路,采用两级树形交换网络,根节点总带宽约100 - 200Gbps,机器间往返时延小于1毫秒。
- 运行环境:集群内存约1 - 1.5GB被其他任务占用,程序在周末下午运行,此时CPU、磁盘和网络大多空闲。
- Grep程序性能
- 任务参数:扫描约1TB数据(100亿条100字节记录),查找特定三字符模式(该模式在92,337条记录中出现),输入分块约64MB(M = 15000),输出放一个文件(R = 1)。
- 性能表现:计算开始时输入扫描速率随分配机器增多而提升,1764个工作节点分配时速率超30GB/s,约80秒时因Map任务完成速率降为零,总计算耗时约150秒(含约1分钟启动开销,开销源于程序分发和与GFS交互获取输入文件及优化信息)。
- Sort程序性能
- 任务参数:对约1TB数据(100亿条100字节记录)排序,输入分块64MB(M = 15000),排序输出分区为4000个文件(R = 4000),使用内置分区函数(根据键的初始字节分区)。
- 性能表现
- 正常执行:输入读取速率峰值约13GB/s,因Sort的Map任务需写中间输出到本地磁盘,耗时约一半时间和I/O带宽,速率低于Grep。网络传输(shuffle)在第一个Map任务完成后开始,分两批进行,第一批约1700个Reduce任务,计算约300秒时部分完成开始第二批,约600秒完成shuffle。Reduce任务排序后写输出文件,因机器忙于排序中间数据,在shuffle结束后有延迟,写入速率约2 - 4GB/s,约850秒完成,总计算含启动开销耗时891秒,与TeraSort基准测试结果相近。输入速率高于shuffle和输出速率得益于本地性优化,shuffle速率高于输出速率因输出需写两份排序数据(底层文件系统为保证可靠性和可用性采用复制机制,若用纠删码可降低网络带宽需求)。
- 禁用备份任务影响:禁用备份任务时,计算有很长尾部,最后几个Reduce任务耗时久,总计算时间增加44%,达1283秒。
- 机器故障影响:模拟计算中200个工作进程被杀(机器正常,集群调度系统会重启新进程),工人死亡导致输入速率为负(部分已完成Map工作需重做),但重执行较快,总计算含启动开销耗时933秒,仅比正常执行时间增加5%。通过这些测试,全面展示了MapReduce在不同情况下的性能特点和稳定性,为评估其在实际大规模数据处理中的适用性提供了依据。
6. 应用与经验(Applications and Experience)
- 在 Google 内部的实际应用(如索引构建、数据挖掘等)
- MapReduce 的优势和成功因素
- 使用统计和开发历史
这部分主要讲述了MapReduce在大规模索引系统中的应用及带来的好处,具体内容如下:
- 应用背景:MapReduce被用于重写谷歌生产环境中的索引系统,该索引系统的输入是由爬虫系统获取并存储在GFS中的大量文档,原始数据量超过20TB,索引过程由一系列五到十个MapReduce操作组成。
- 带来的好处
- 简化代码:使用MapReduce后,处理容错、分布和并行化的代码被隐藏在库中,使得索引代码更简单、更小且更易于理解。例如,某一计算阶段的代码量从约3800行C++代码减少到约700行。
- 便于更改索引过程:MapReduce库性能良好,使得可以将概念上不相关的计算分开,而不是混合在一起以避免多次处理数据,这使得更改索引过程变得容易。例如,在旧系统中需要数月才能完成的更改,在新系统中仅需几天即可实现。
- 操作更便捷:MapReduce库自动处理了大部分由机器故障、慢速机器和网络问题引起的问题,无需操作员干预,使得索引过程更易于操作。此外,通过向索引集群添加新机器可轻松提高性能,体现了良好的可扩展性和鲁棒性,确保了索引系统在大规模数据处理场景下的高效稳定运行。
7. 相关工作(Related Work)
- 相关编程模型(如 Bulk Synchronous Programming、MPI)
- 比较与创新点
8. 总结(Conclusions)
- MapReduce 的主要特点与意义
- 对分布式计算的启发和贡献
- 成功原因
- 易用性:模型对程序员友好,即使无并行和分布式系统经验的程序员也能轻松上手,因为它隐藏了并行化、容错、本地优化和负载均衡等复杂细节。
- 广泛适用性:众多问题都能以 MapReduce 计算形式表达,如用于谷歌生产网页搜索服务的数据生成、排序、数据挖掘、机器学习等多种系统。
- 高效实现:开发的 MapReduce 实现可扩展到数千台机器的大型集群,能高效利用机器资源,适用于谷歌面临的大规模计算问题。
- 经验教训
- 编程模型限制的优势:限制编程模型便于并行化、分布式计算和实现容错。
- 网络带宽优化的重要性:网络带宽是稀缺资源,系统中的本地性优化(从本地磁盘读取数据、将中间数据写本地磁盘)可减少网络数据传输。
- 冗余执行的作用:冗余执行可降低慢速机器影响,处理机器故障和数据丢失问题。通过总结,强调了 MapReduce 在大规模数据处理中的价值和意义,为其进一步发展和应用提供了理论支持和实践经验。