go 学习路线#
GoLang语法新奇#
golang 中的表达式,加";“与不加都可以,建议不加
另外函数方法中的{},符合 java 中的标准,需要放在函数名后面
变量声明#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| package main
import "fmt"
/*
四种变量声明方式
*/
var x, y int
var ( //这种分解的写法,一般用于声明全局变量
a int
b bool
)
func main() {
//声明变量 默认为 0 var count int
fmt.Println("count = ", count)
// 方法二 声明变量,并初始化
var score int = 100
fmt.Println("score = ", score)
//方法三 (不推荐) 初始化省去数据类型,通过值来自动匹配数据类型
var value = 100
fmt.Println("value = ", value)
// 方法四:(最常用的方法),只能用在函数体内
temperature := 100
fmt.Println("temperature = ", temperature)
fmt.Printf("type of temperature = %T", temperature)
}
|
常量声明#
1
2
3
4
5
6
| package main
import "unsafe"
const ( a = "abc" b = len(a) c = unsafe.Sizeof(a) )
func main(){
println(a, b, c)
}
|
可以使用关键字iota在 const() 里,用来进行累加的
1
2
3
4
5
6
7
8
9
| const (
Apple, Banana = iota + 1, iota + 2
Cherimoya, Durian
Elderberry, Fig
)
|
返回值#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| package main
import "fmt"
func printMessageWithValue(message string, value int) int {
fmt.Println("message:", message, "value:", value)
result := 1024
return result
}
// 可以返回多个返回值,匿名
func calculateDoubleValues(message string, value int) (int, int) {
fmt.Println("message:", message, "value:", value)
baseValue := 1024
return baseValue, baseValue
}
// 可以返回多个返回值,有形参名称
func calculateSingleAndDouble(message string, value int) (singleValue int, doubleValue int) {
fmt.Println("message:", message, "value:", value)
baseResult := 1024
singleValue = baseResult
doubleValue = baseResult * 2
return
}
// 形参名称可以一起定义,都有默认值 0func getDefaultValues() (firstValue, secondValue int) {
firstValue = 1
secondValue = 2
return
}
func main() {
result := printMessageWithValue("hello", 100)
fmt.Println(result)
returnValue1, returnValue2 := calculateDoubleValues("hello", 100)
fmt.Println("returnValue1:", returnValue1, "returnValue2:", returnValue2)
returnValue1, returnValue2 = calculateSingleAndDouble("hello", 100)
fmt.Println("returnValue1:", returnValue1, "returnValue2:", returnValue2)
}
|
import#
golang里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package main)。这两个函数在定义时不能有任何的参数和返回值。
虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
go程序会自动调用init()和main(),所以你不需要在任何地方调用这两个函数。每个package中的init函数都是可选的,但package main就必须包含一个main函数。
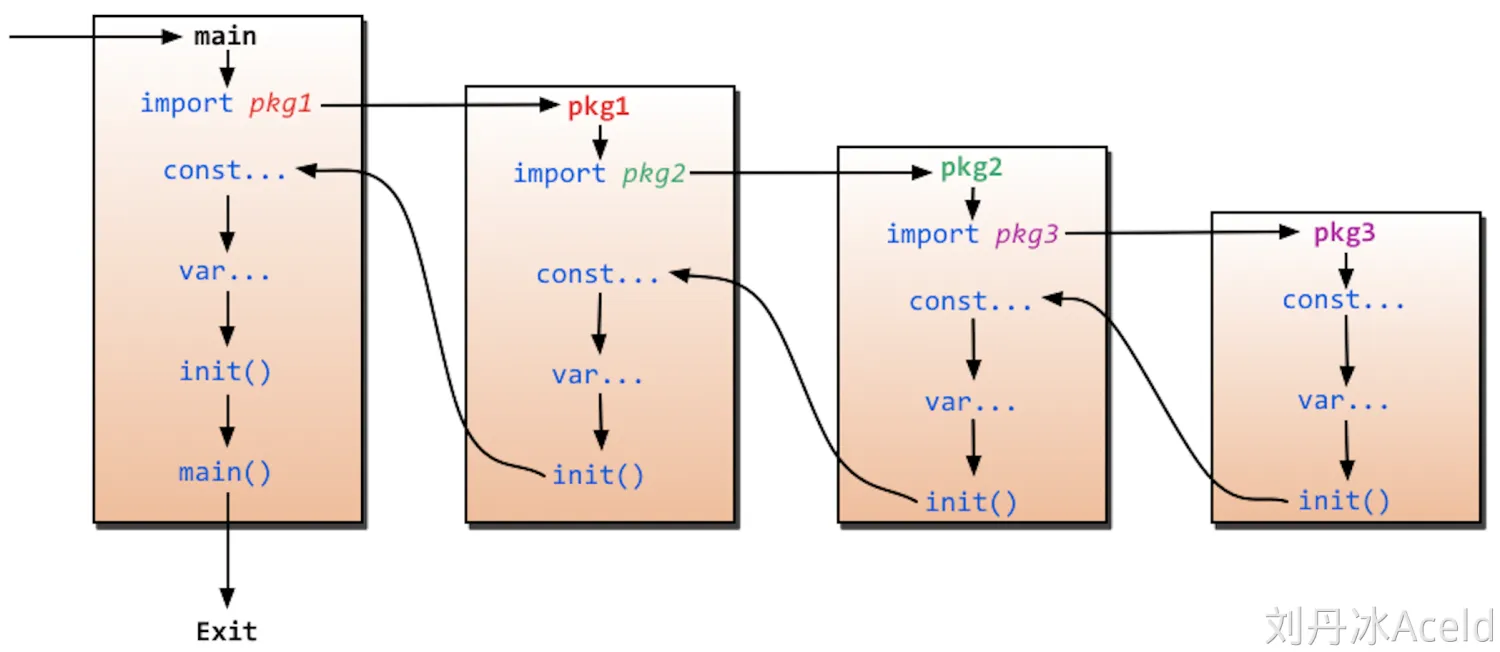
程序的初始化和执行都起始于main包。
如果main包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。
当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。
等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下图详细地解释了整个执行过程:
导入时候的记得要加路径,从项目最开始的地方开始
import _ "fmt"给 fmt 包起别名,匿名,无法使用当前包的方法,但是会执行当前包内部的init() 方法
import aa "fmt"给 fmt 包起别名aa, fmt.Println 可以直接用 aa.Println 代替
import . "fmt"将当前fmt 包中的全部方法,导入到当前本包中,fmt 包中的所有方法可以直接使用 API 进行调用,无需使用 fmt.API 的形式
跟 c 类似,这里就不做阐述
panic#
panic 是 Go 的内置函数,用于触发一个运行时错误(称为 “panic”),它会立即中止当前函数的执行,开始进行错误处理流程,最终结束程序(除非通过 recover 捕获并处理该 panic)。
使用 panic 可以确保在函数或方法的必要实现部分被遗忘时,程序不会在未完成的状态下静默运行,而是明确地失败。
1
2
3
4
5
6
7
8
9
| type MyInterface interface {
DoSomething()
}
type MyImplementation struct {}
func (m MyImplementation) DoSomething() {
panic("implement me")
}
|
defer#
相当于 Java 中的 finally ,用于最后执行的东西。
defer 在 return 后面执行
defer 语句属于压栈的模式,先进后出
应用场景
defer语句会将其后的函数调用推迟到当前函数执行结束时执行。这个特性常用于处理成对的操作,如打开/关闭文件、获取/释放锁、连接/断开连接等,确保资源被适当地释放,即使在发生错误或提前返回的情况下也能保证执行。
切片 slice#
Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
定义切片#
你可以声明一个未指定大小的数组来定义切片:
切片不需要说明长度。
或使用make()函数来创建切片:
1
| var slice1 []type = make([]type, len)
|
也可以简写为
1
| slice1 := make([]type, len)
|
也可以指定容量,其中capacity为可选参数。 意为数组的当前的最大长度,如果数组的 len 比 cap 要大,则 cap *= 2 ,进行扩容,若不指定,则初始的 cap = len
1
| make([]T, length, capacity)
|
这里 len 是数组的长度并且也是切片的初始长度。
判断是否为空#
1
2
3
4
5
6
| // 判断 slice 是否为空
if slice == nil {
fmt.Println("slice is empty")
} else {
fmt.Println("slice is not empty")
}
|
好奇怪,在 go 里这个关键字叫 nil
切片的添加#
使用 append 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| var numbers []int
printSlice(numbers)
/* 允许追加空切片 */
numbers = append(numbers, 0)
printSlice(numbers)
/* 向切片添加一个元素 */
numbers = append(numbers, 1)
printSlice(numbers)
/* 同时添加多个元素 */
numbers = append(numbers, 2,3,4)
printSlice(numbers)
|
切片的截取#
1
| s1 := s[0:2] // 是左闭右开的区间,不写就默认头或尾
|
这些只是浅拷贝,如果原数组内的值更改,则截取原数组的数组内的值也会进行改变,如果不想出现这种情况则需要深拷贝 copy
1
2
3
4
5
6
7
| /* 创建切片 numbers1 是之前切片的两倍容量*/
numbers1 := make([]int, len(numbers), (cap(numbers))*2)
/* 拷贝 numbers 的内容到 numbers1 */
copy(numbers1,numbers)
|
map#
map 的声明#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| //第一种声明,key 是 string, value 也是 string
var test1 map[string]string
//在使用map前,需要先make,make的作用就是给map分配数据空间
test1 = make(map[string]string, 10)
test1["one"] = "php"
test1["two"] = "golang"
test1["three"] = "java"
fmt.Println(test1) //map[two:golang three:java one:php]
//第二种声明
test2 := make(map[string]string)
test2["one"] = "php"
test2["two"] = "golang"
test2["three"] = "java"
fmt.Println(test2) //map[one:php two:golang three:java]
//第三种声明
test3 := map[string]string{
"one" : "php",
"two" : "golang",
"three" : "java",
}
fmt.Println(test3) //map[one:php two:golang three:java]
|
map 的操作#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| language := make(map[string]map[string]string)
language["php"] = make(map[string]string, 2)
language["php"]["id"] = "1"
language["php"]["desc"] = "php是世界上最美的语言"
language["golang"] = make(map[string]string, 2)
language["golang"]["id"] = "2"
language["golang"]["desc"] = "golang抗并发非常good"
fmt.Println(language) //map[php:map[id:1 desc:php是世界上最美的语言] golang:map[id:2 desc:golang抗并发非常good]]
//增删改查
val, key := language["php"] //查找是否有php这个子元素
if key {
fmt.Printf("%v", val)
} else {
fmt.Printf("no");
}
language["php"]["id"] = "3" //修改了php子元素的id值
language["php"]["nickname"] = "啪啪啪" //增加php元素里的nickname值
delete(language, "php") //删除了php子元素
fmt.Println(language)
for key, value := range language {
}// 遍历
// 如果其中 key 无需使用的话,可以写成
for _, value := range language {
}
|
map存储是无序的,遍历 Map 时返回的键值对的顺序是不确定
结构体 struct#
结构体的样式和 c 很像,类似于
1
2
3
4
5
6
7
| type Book sturct {
title string
auth string
}
// 创建新对象
var book1 Book
|
结构体标签#
在结构体标签中,有类似于文档注释的东西,方便你了解怎么使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| package main
import (
"fmt"
"reflect"
)
type resume struct {
Name string `json:"name" doc:"我的名字"` //注意是反引号
}
func findDoc(stru interface{}) map[string]string {
t := reflect.TypeOf(stru).Elem()
doc := make(map[string]string)
for i := 0; i < t.NumField(); i++ {
//这里就是通过标签来获得值
doc[t.Field(i).Tag.Get("json")] = t.Field(i).Tag.Get("doc")
}
return doc
}
func main() {
var stru resume
doc := findDoc(&stru)
fmt.Printf("name字段为:%s\n", doc["name"])
}
|
结构体标签应用#
在标签处添加 json 编解码
orm 映射关系
这些需要时再去了解
interface与类型断言#
interface接口的使用/多态#
接口的创建方式(父类)
1
2
3
4
5
| type Animal interface {
Sleep()
GetColor() string
GetType() string
}
|
子类(直接实现父类的全部接口),注意,在结构体中的函数,好像基本上都需要加上(结构体名称 * 结构体类型),这样是为了方便在 new 完的对象后直接使用方法?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| type Cat struct {
color string
}
// 这里 (this *Cat) 就是对象的方法
func (this *Cat) Sleep() {
fmt.Println("this cat is sleep")
}
func (this *Cat) GetColor() string {
return this.color
}
func (this *Cat) GetType() string {
return "Cat"
}
|
只要实现了所有的方法,那么这个子类就相当于父类的继承,类似于
1
2
3
| var animal Animal // 接口的数据类型,父类指针,注意是指针!
animal = &Cat{"Green"}
animal.Sleep() // 这里调用的将会是 Cat 的 Sleep() 方法,多态的体现了,因为本身是 Animal 类
|
interface() 空接口#
这是一个通用万能类型
int、string、float32、float64、struct 都实现了 interface()
泛型,object?
1
2
3
4
5
6
7
8
9
10
| func muFunc(arg interface{}) {
fmt.Println("myFunc is called")
fmt.Println(arg)
}
func main() {
myFunc(100)
myFunc("abc")
myFunc(3.14)
}
|
这些都能够成功输出,所以这个函数的入参什么都可以
类型断言#
Golang的语言中提供了断言的功能。golang中的所有程序都实现了interface{}的接口,这意味着,所有的类型如string,int,int64甚至是自定义的struct类型都就此拥有了interface{}的接口,这种做法和java中的Object类型比较类似。那么在一个数据通过func funcName(interface{})的方式传进来的时候,也就意味着这个参数被自动的转为interface{}的类型。
1
2
3
4
5
| func funcName(a interface{}) string {
return string(a)
}
|
编译器会返回
1
| cannot convert a (type interface{}) to type string: need type assertion
|
此时,意味着整个转化的过程需要类型断言。
1
2
3
| var a interface{}
value, ok := a.(string) //前面是接受接口的值,后面是判断类型是否正确,是 bool
|
反射reflect#
变量的结构#
type 和 value 组成的 pair 是变量的结构
其中 type 可以分为 static type 和 concrete type,前者是基本的类型,比如 int,string,后者是具体的数据类型,虽然我并不是很清楚什么是具体(具体创造的类?)
断言有两步:得到动态类型 type,判断 type 是否实现了目标接口。
反射的原理就是基于interface 的 pair 来实现的
反射的应用#
jreflect.Value是通过reflect.ValueOf(X)获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| package main
import (
"fmt"
"reflect"
)
func main() {
var num float64 = 1.2345
fmt.Println("old value of pointer:", num)
// 通过reflect.ValueOf获取num中的reflect.Value,注意,参数必须是指针才能修改其值
pointer := reflect.ValueOf(&num)
newValue := pointer.Elem()
fmt.Println("type of pointer:", newValue.Type())
fmt.Println("settability of pointer:", newValue.CanSet())
// 重新赋值
newValue.SetFloat(77)
fmt.Println("new value of pointer:", num)
// 如果reflect.ValueOf的参数不是指针,会如何?
pointer = reflect.ValueOf(num)
// newValue = pointer.Elem()
// 如果非指针,这里直接panic,
// “panic: reflect: call of reflect.Value.Elem on float64 Value”
}
运行结果:
old value of pointer: 1.2345
type of pointer: float64
settability of pointer: true
new value of pointer: 77
|
GoLang 高阶#
理论知识#
协程并发#
协程:coroutine。也叫轻量级线程。
与传统的系统级线程和进程相比,协程最大的优势在于“轻量级”。可以轻松创建上万个而不会导致系统资源衰竭。而线程和进程通常很难超过1万个。这也是协程别称“轻量级线程”的原因。
一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
多数语言在语法层面并不直接支持协程,而是通过库的方式支持,但用库的方式支持的功能也并不完整,比如仅仅提供协程的创建、销毁与切换等能力。如果在这样的轻量级线程中调用一个同步 IO 操作,比如网络通信、本地文件读写,都会阻塞其他的并发执行轻量级线程,从而无法真正达到轻量级线程本身期望达到的目标。
在协程中,调用一个任务就像调用一个函数一样,消耗的系统资源最少!但能达到进程、线程并发相同的效果。
在一次并发任务中,进程、线程、协程均可以实现。从系统资源消耗的角度出发来看,进程相当多,线程次之,协程最少。
Go并发#
Go 在语言级别支持协程,叫goroutine。Go 语言标准库提供的所有系统调用操作(包括所有同步IO操作),都会出让CPU给其他goroutine。这让轻量级线程的切换管理不依赖于系统的线程和进程,也不需要依赖于CPU的核心数量。
有人把Go比作21世纪的C语言。第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持并发。同时,并发程序的内存管理有时候是非常复杂的,而Go语言提供了自动垃圾回收机制。
Go语言为并发编程而内置的上层API基于顺序通信进程模型CSP(communicating sequential processes)。这就意味着显式锁都是可以避免的,因为Go通过相对安全的通道发送和接受数据以实现同步,这大大地简化了并发程序的编写。
Go语言中的并发程序主要使用两种手段来实现。goroutine和channel。
什么是Goroutine#
goroutine是Go语言并行设计的核心,有人称之为go程。 Goroutine从量级上看很像协程,它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享。执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。也正因为如此,可同时运行成千上万个并发任务。goroutine比thread更易用、更高效、更轻便。
一般情况下,一个普通计算机跑几十个线程就有点负载过大了,但是同样的机器却可以轻松地让成百上千个goroutine进行资源竞争。
Goroutine#
核心语法#
在 func 前添加 go ,只需在函数调⽤语句前添加 go 关键字,就可创建并发执⾏单元。开发⼈员无需了解任何执⾏细节,调度器会自动将其安排到合适的系统线程上执行。
在并发编程中,我们通常想将一个过程切分成几块,然后让每个 goroutine 各自负责一块工作,当一个程序启动时,主函数在一个单独的 goroutine 中运行,我们叫它main goroutine 。新的 goroutine 会用 go 语句来创建。而go语言的并发设计,让我们很轻松就可以达成这一目的。
具体用法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| func backgroundCounterTask() {
counter := 0
for {
counter++
fmt.Printf("new goroutine: counter = %d\n", counter)
time.Sleep(1*time.Second) //延时1s
}
}
func main() {
//创建一个 goroutine,启动另外一个任务
go backgroundCounterTask()
mainCounter := 0
//main goroutine 循环打印
for {
mainCounter++
fmt.Printf("main goroutine: mainCounter = %d\n", mainCounter)
time.Sleep(1 * time.Second) //延时1s
}
}
|
主 goroutine 退出后,其它的工作 goroutine 也会自动退出
Channel#
channel 的定义#
channel是Go语言中的一个核心类型,可以把它看成管道。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。
channel是一个数据类型,主要用来解决go程的同步问题以及go程之间数据共享(数据传递)的问题。
goroutine运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
引⽤类型 channel可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全。
定义 channel 变量#
和 map 类似,channel 也一个对应 make 创建的底层数据结构的引用。
当我们复制一个 channel 或用于函数参数传递时,我们只是拷贝了一个 channel 引用,因此调用者和被调用者将引用同一个 channel 对象。和其它的引用类型一样,channel 的零值也是 nil 。
定义一个 channel 时,也需要定义发送到 channel 的值的类型。channel 可以使用内置的 make() 函数来创建:
chan 是创建 channel 所需使用的关键字。Type 代表指定 channel 收发数据的类型。
1
2
3
| make(chan Type) //等价于make(chan Type, 0)
make(chan Type, capacity)
|
当 参数capacity= 0 时,channel 是无缓冲阻塞读写的;当capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity 个元素才阻塞写入。
我个人的理解就是,类似于信号量对于线程之间的进行互斥和同步的操作。
channel 的通信#
channel非常像生活中的管道,一边可以存放东西,另一边可以取出东西。channel通过操作符 <- 来接收和发送数据,发送和接收数据语法:
1
2
3
4
| channel <- value //发送value到channel
<-channel //接收并将其丢弃
x := <-channel //从channel中接收数据,并赋值给x
x, ok := <-channel //功能同上,同时检查通道是否已关闭或者是否为空
|
仔细分析 channel 的 ok 的各种情况
当通道是 打开状态 且有值发送时,ok 为 true。此时 x 将接收到通道中的值。
当通道 开启但是没有数据 时,ok 并不会立即返回,而是会阻塞,直到通道中有数据可读或者
通道被关闭。当有数据时,ok 变成 true;如果channel 被关闭,ok 变成 false
当通道 关闭但是有数据 时,ok 返回 true
当通道 关闭并且没有数据 时, ok 返回 false
通过循环读取 channel 中的值时,语法可以使用 range 这么写:
1
2
3
4
5
6
7
8
9
10
11
12
13
| for {
if data, ok := <-dataChannel; ok {
fmt.PrintLn(data)
} else {
break
}
}
// 也可以使用 range 直接来实现
for data := range dataChannel {
fmt.Println(data)
}
fmt.Println("Main finished..")
|
**当 capacity 为 0 时
很明显,这就是一个互斥锁,用来支持同步的。
emmm ,我觉得我说的有些问题。因为互斥锁是限制 P 的,而不能限制 V。而这里的 channel 是 P 和 V 都限制的。只有同时都到,才能都继续往下进行。就像下面这张图:
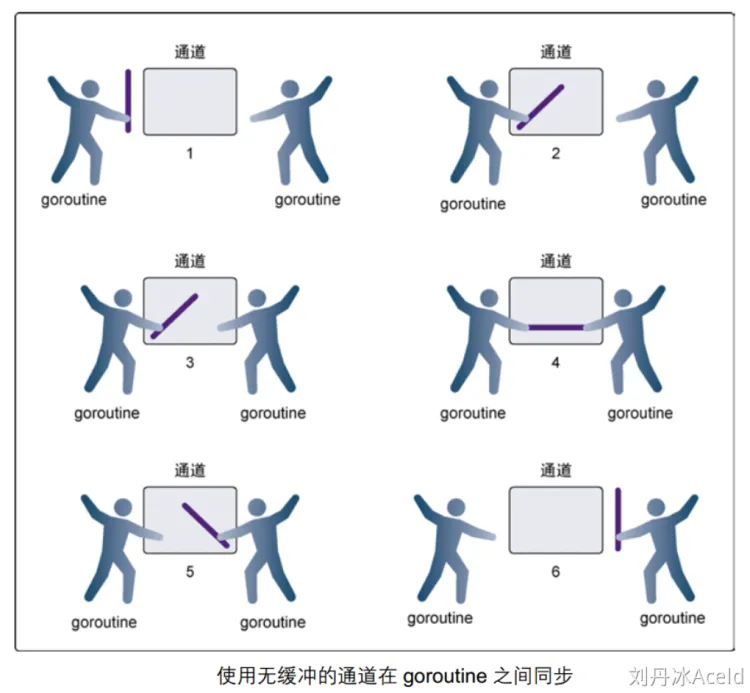
- 在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。
- 在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
- 在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。
- 在第 4 步和第 5 步,进行交换,并最终,在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做其他事情了。
**当 capacity 不为 0 时
通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
借助函数 len(ch) 求取缓冲区中剩余元素个数, cap(ch) 求取缓冲区元素容量大小。
1
2
| bufferedChannel := make(chan int, 3) //带缓冲的通道
fmt.Printf("子go程正在运行[%d]: len(bufferedChannel)=%d, cap(bufferedChannel)=%d\n", i, len(bufferedChannel), cap(bufferedChannel))
|
关闭 channel#
如果发送者知道,没有更多的值需要发送到 channel 的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的 close 函数来关闭 channel 实现。
1
2
| intChannel := make(chan int) // 创建 channel
close(intChannel) // 关闭 channel
|
单向 channel#
单向channel变量的声明非常简单,如下:
1
2
3
| var bidirectionalChannel chan int // bidirectionalChannel是一个正常的channel,是双向的
var writeOnlyChannel chan<- float64 // writeOnlyChannel是单向channel,只用于写float64数据
var readOnlyChannel <-chan int // readOnlyChannel是单向channel,只用于读int数据
|
这么看我觉得挺抽象的,我感觉得看下面这个,具体语法就是 进去的是输入 chan<- ,出来的是输出 <-chan
1
2
3
4
5
6
7
8
9
10
11
12
13
| baseChannel := make(chan int, 3)
var sendOnlyChannel chan<- int = baseChannel // send-only
var receiveOnlyChannel <-chan int = baseChannel // receive-only
sendOnlyChannel <- 1
//<-sendOnlyChannel //invalid operation: <-sendOnlyChannel (receive from send-only type chan<- int)
<-receiveOnlyChannel
//receiveOnlyChannel <- 2 //invalid operation: receiveOnlyChannel <- 2 (send to receive-only type <-chan int)
//不能将单向 channel 转换为普通 channel
convertedChannel1 := (chan int)(sendOnlyChannel) //cannot convert sendOnlyChannel (type chan<- int) to type chan int
convertedChannel2 := (chan int)(receiveOnlyChannel) //cannot convert receiveOnlyChannel (type <-chan int) to type chan int
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| // chan<- //只写
func produceNumbers(outputChannel chan<- int) {
defer close(outputChannel)
for i := 0; i < 5; i++ {
outputChannel <- i //如果对方不读 会阻塞
}
}
// <-chan //只读
func printNumbers(inputChannel <-chan int) {
for num := range inputChannel {
fmt.Println(num)
}
}
func main() {
numberChannel := make(chan int) // chan //读写
go produceNumbers(numberChannel) //生产者
printNumbers(numberChannel) //消费者
fmt.Println("done")
}
|
Select#
select作用#
Go里面提供了一个关键字select,通过select可以监听channel上的数据流动。
有时候我们希望能够借助channel发送或接收数据,并避免因为发送或者接收导致的阻塞,尤其是当channel没有准备好写或者读时。select语句就可以实现这样的功能。
select的用法与switch语言非常类似,由select开始一个新的选择块,每个选择条件由case语句来描述。
与switch语句相比,select有比较多的限制,其中最大的一条限制就是每个case语句里必须是一个IO操作,大致的结构如下:
1
2
3
4
5
6
7
8
| select {
case <- inputChannel:
// 如果inputChannel成功读到数据,则进行该case处理语句
case outputChannel <- 1:
// 如果成功向outputChannel写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
|
在一个select语句中,Go语言会按顺序从头至尾评估每一个发送和接收的语句。
如果其中的任意一语句可以继续执行(即没有被阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有任意一条语句可以执行(即所有的通道都被阻塞),那么有两种可能的情况:
Go Modules#
go mod 命令#
| 命令 | 作用 |
|---|
| go mod init | 生成 go.mod 文件 |
| go mod download | 下载 go.mod 文件中指明的所有依赖 |
| go mod tidy | 整理现有的依赖 |
| go mod graph | 查看现有的依赖结构 |
| go mod edit | 编辑 go.mod 文件 |
| go mod vendor | 导出项目所有的依赖到vendor目录 |
| go mod verify | 校验一个模块是否被篡改过 |
| go mod why | 查看为什么需要依赖某模块 |
go mod环境变量#
可以通过 go env 命令来进行查看
1
2
3
4
5
| $ go env GO111MODULE="auto"
GOPROXY="https://proxy.golang.org,direct"
GONOPROXY="" GOSUMDB="sum.golang.org"
GONOSUMDB="" GOPRIVATE=""
...
|
GOPROXY#
这个环境变量主要是用于设置 Go 模块代理(Go module proxy),其作用是用于使 Go 在后续拉取模块版本时直接通过镜像站点来快速拉取。
GOPROXY 的默认值是:https://proxy.golang.org,direct
proxy.golang.org国内访问不了,需要设置国内的代理.
而在刚刚设置的值中,我们可以发现值列表中有 “direct” 标识,它又有什么作用呢?
实际上 “direct” 是一个特殊指示符,用于指示 Go 回源到模块版本的源地址去抓取(比如 GitHub 等),场景如下:当值列表中上一个 Go 模块代理返回 404 或 410 错误时,Go 自动尝试列表中的下一个,遇见 “direct” 时回源,也就是回到源地址去抓取,而遇见 EOF 时终止并抛出类似 “invalid version: unknown revision…” 的错误。
GOSUMDB#
它的值是一个 Go checksum database,用于在拉取模块版本时(无论是从源站拉取还是通过 Go module proxy 拉取)保证拉取到的模块版本数据未经过篡改,若发现不一致,也就是可能存在篡改,将会立即中止。
GONOPROXY/GONOSUMDB/GOPRIVATE#
这三个环境变量都是用在当前项目依赖了私有模块,例如像是你公司的私有 git 仓库,又或是 github 中的私有库,都是属于私有模块,都是要进行设置的,否则会拉取失败。
实践 即时通讯项目#
func init()#
func init() 是 Go 语言中的特殊函数,它会自动执行。具体来说,init() 函数的执行时间是程序启动时,在 main() 函数运行之前执行。你不需要显式调用 init(),Go 运行时会自动调用它。
关于 init() 的执行顺序:
每个文件中的 init() 函数会在该文件被导入并初始化时执行。
多个文件中的 init() 函数按照包的依赖顺序执行。
在同一个文件中,init() 函数的执行顺序是从上到下执行,在全局变量初始化之后、main() 函数之前执行。
Go语言高性能编程手册(万字长文)